
Simplifying computational biology (for people building life sciences companies and products)
Computational Biologists, Bioinformaticians, and Bioinformatics Scientists encompass a highly diverse group of people and skill sets. As a founder or leader, how do you sort through the wide spectrum of skills, training, and experience to find the right technical experts who can execute efficiently and also fit with your company’s mission and culture?
Recruiters can help somewhat, but even if you have a strong stack of resumes, there’s often a jigsaw puzzle of interrelated tasks or deliverables that founders need to solve for to build a high-performance team. At a minimum, you want someone who can do computational analysis of large and complex data, write good code, and communicate clearly with their teammates. What else do you need, and how many distinct functions or skill sets are involved in building your product or platform?
I enjoy helping founders figure out what their puzzle looks like and how to put the pieces together. For example, for a therapeutics startup I recently worked with, a lot of the early conversation was around questions like: Do you mostly need to analyze large data sets using established tools and methods to identify targets? Or will your drug discovery platform have some novel computational methods baked into it? The answers to such questions can get you on the path to finding the right people for your nascent team. They can also be critical to your company’s value proposition and chances of securing future funding.
Here are some guidelines that I like to use when working with founders or biotech leaders who are building a computational team. To clarify and simplify the team building process, I like to think of Computational Biology* as a collection of subdisciplines or job functions** within a company:
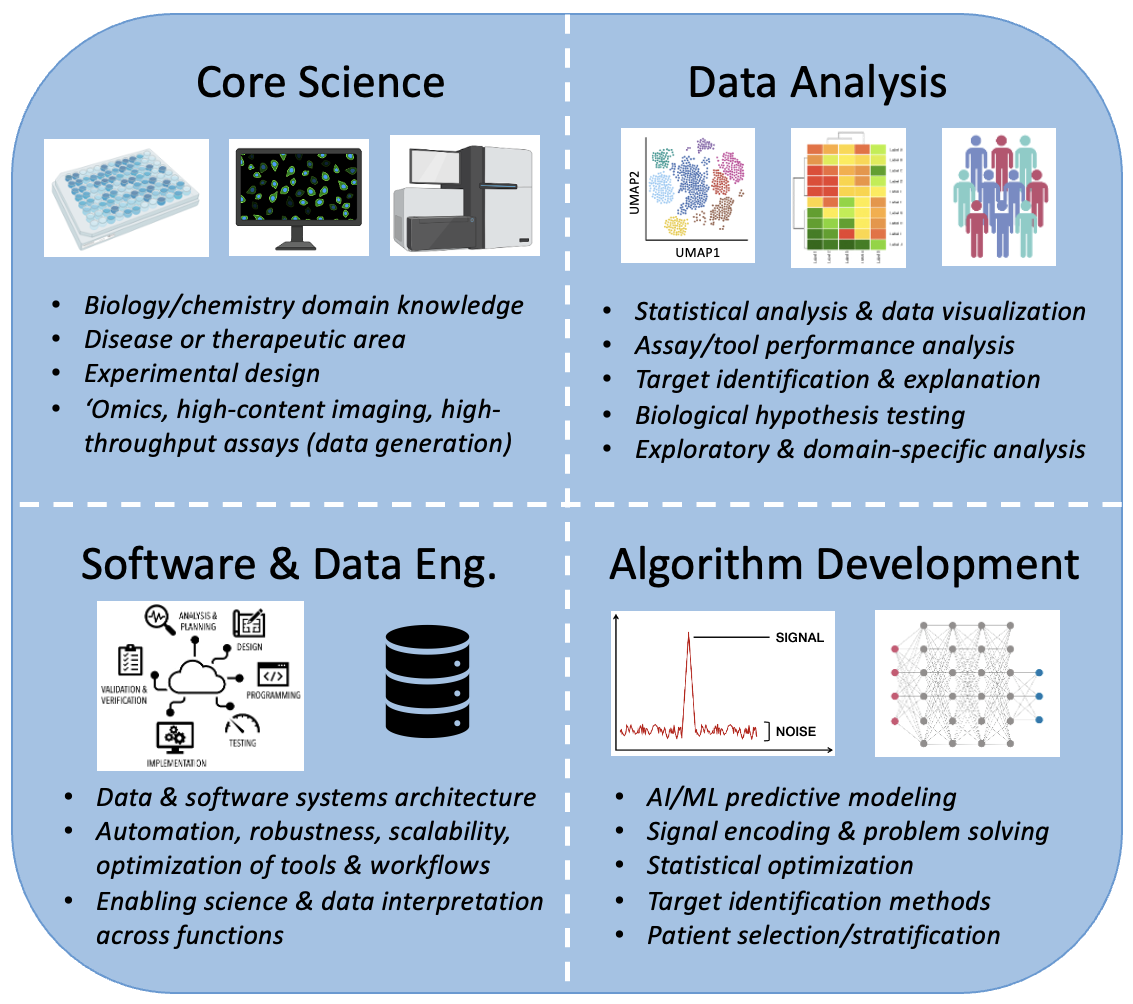
Figure 1. Four pillars of applied computational biology: subdisciplines that equate to recurring job functions in a company.
Core Science
Data Analysis
Algorithm Development
Software & Data Engineering
Now we can ask, How does each of these potential job functions fit with what you’re trying to build? (Note that I am not saying that a company needs a “Data Analysis” department per se, just that this is a recurring job function that needs to be carefully considered. There also aren’t necessarily hard lines between these functions, they can and do overlap in practice.)

Figure 2. These four job functions are distinct but sometimes overlap in practice. Separate areas of each circle indicate a recurring job function in a company. In practice, these domain areas and job functions can overlap, and this overlap is critical to developing a life sciences product using applied computational biology. (For example, someone doing much of the data analysis should also be able to participate in experimental design and have key scientific domain knowledge. Also, in an ideal world, everyone involved in the cross-functional team should be able to program and understand code, to varying extents.)
Very few people, if any, are able to truly excel at more than two of the four job functions mentioned above. Yet startups hiring computational biologists or bioinformaticians often default to trying to hire a “jack of all trades” due to resource constraints or not fully understanding how each function above contributes to their core value proposition and ability to execute. Each bioinformatician or computational biologist is going to have specific strengths and weaknesses across these domains. Finding someone who understands the biological application space can be particularly limiting, but these folks may also represent your best hires. Given the above, my conversation with a founder would then turn to: What do your resources look like, and what functions are truly mission critical and need to be built first?
Once we know which of these functions you need on your team, we can craft well-defined job descriptions and look for the appropriate skill sets.
To anyone thinking, “I’m building an AI/ML platform, I just need to hire a computational biologist who is an expert at machine learning”, I would say: The same principles outlined above apply to Data Science and Machine Learning for life science or health care product development. (In this case, the AI/ML model fits within the umbrella of Algorithm Development, whereas the platform and team spans all four functions.) If a sophisticated deep learning model is core to your platform, you likely want at least one well-trained, experienced ML scientist/engineer and probably also a computational biologist to stand up your AI/ML model and ensure it can make the right predictions. In addition to the necessary coding, architecting, and software + data systems management, this hypothetical lean, two-person team*** also needs to perform data analysis related to inputs and outputs of their model (evaluating performance, ensuring a well-balanced training data set), to understand the relationship of the model and its predictions to the core biology/chemistry, and to communicate their results clearly. I’ve previously worked in this computational biologist capacity to develop a ML-based personalized therapeutics platform, and in doing so have also served as an interface or translator between the computational ML team and “wet lab” biologists. It’s an essential role that is often overlooked.
(More on acting as a translator in future blog posts.)
I want to acknowledge Darya Chudova and Aviv Regev for inspiration, particularly on the “four pillars” concept. I have been lucky to work with these and other great biotech leaders throughout my career.
* For the purposes of this post, I use the terms “computational biology” and “bioinformatics” interchangeably.
** Note that I have left out the critical functions of Systems Admin & IT, as these roles are not necessarily focused on science per se. Systems Admin & IT are nonetheless foundational for anything computational and mission critical for most organizations.
*** Note that I would not recommend a two-person team in this scenario, except in rare cases.